

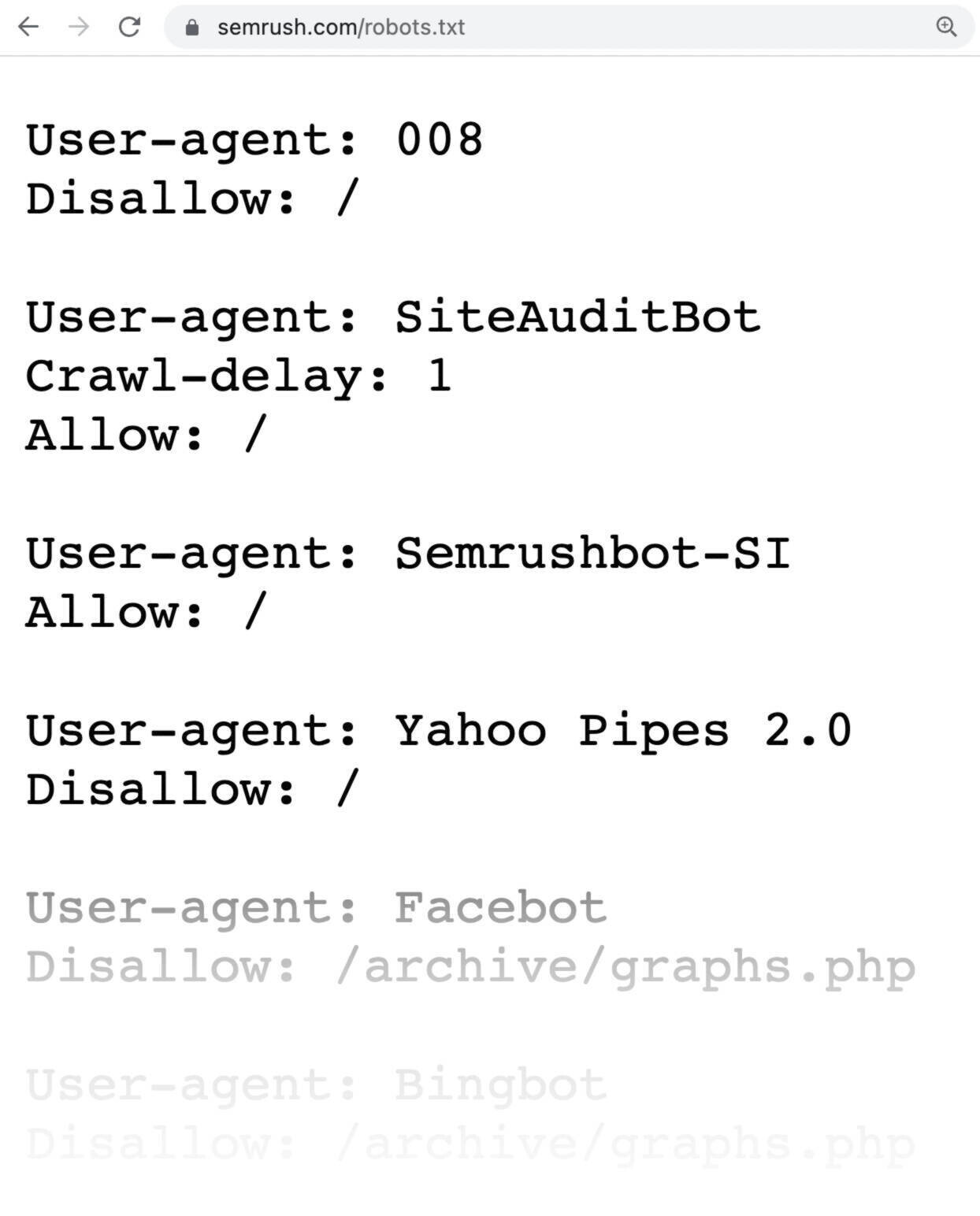
To block a spam domain in robots.txt, add “Disallow: /” under the User-agent directive for that domain. This prevents search engines from crawling pages linked to that domain.
Blocking spam domains in your robots. txt file is essential for maintaining a healthy and efficient website. Spam domains can negatively impact your site’s SEO and user experience. By specifying which domains search engines should not crawl, you can protect your website’s integrity.
This simple yet effective method ensures that unwanted traffic is minimized. Regularly updating your robots. txt file keeps your site optimized and free from spam-related issues. Follow these steps to keep your website clean and user-friendly. Proper management of your robots. txt file is crucial for long-term success in search engine rankings.
Introduction To Robots.txt
The robots.txt file is a simple text file that lives in your website’s root directory. It plays a crucial role in guiding search engine bots on how to crawl your website. Understanding its usage can help you manage your site’s visibility on search engines effectively.
Purpose Of Robots.txt
The primary purpose of robots.txt is to instruct search engine bots on which pages to crawl and index. This file helps in:
- Controlling web crawlers’ access to your site.
- Preventing the indexing of certain pages.
- Reducing server load by managing bot traffic.
Here’s a simple example of a robots.txt file:
User-agent:
Disallow: /private-directory/
This file tells all bots not to enter the /private-directory/ folder.
Importance Of Managing Spam
Managing spam domains in your robots.txt file is crucial for website health. Spam can harm your site’s credibility and SEO performance. Here’s why managing spam is essential:
- Protects your site from malicious bots.
- Improves your site’s loading speed.
- Enhances your site’s user experience.
Blocking spam domains ensures that unwanted bots do not waste your server resources. Below is an example of how to block a spam domain:
User-agent: bad-bot
Disallow: /
This code tells the ‘bad bot’ not to crawl any part of your site.
Understanding Spam Domains
Spam domains can harm your website’s performance. They disrupt user experience and damage your site’s reputation. Understanding these domains helps you protect your website effectively.
What Are Spam Domains?
Spam domains are websites created to send unwanted traffic. They often host low-quality content or malicious links. These domains aim to manipulate search engine rankings or distribute malware.
Typical characteristics of spam domains include:
- High bounce rates
- Low-quality content
- Suspicious URLs
- Frequent changes in content
Recognizing these traits helps you identify and block spam domains quickly.
How They Affect Your Website
Spam domains can negatively impact your website in several ways:
| Impact | Description |
|---|---|
| Reduced SEO Rankings | Spam traffic can lower your site’s search engine rankings. |
| Server Overload | Excessive spam traffic can overload your server, slowing your site. |
| Reputation Damage | Users might associate your site with spam, harming your reputation. |
Preventing these issues is crucial for maintaining a healthy website.
By blocking spam domains in your robots.txt file, you protect your site. This action improves user experience and ensures better SEO performance.
Identifying Spam Domains
Identifying spam domains is crucial for maintaining your website’s health. Spam domains can hurt your site’s SEO and user experience. Learn how to detect these spammy entities effectively.
Tools For Detection
Several tools help you detect spam domains. These tools can make the identification process easier and more accurate.
- Google Search Console: Check your site’s backlinks and look for suspicious domains.
- Ahrefs: Use Ahrefs to analyze your backlink profile and identify spammy links.
- SEMrush: SEMrush provides detailed reports on your site’s backlinks, helping you spot spam domains.
These tools provide valuable insights. They make it easier to keep your site clean.
Manual Identification Methods
Manual methods can also help you identify spam domains. These methods involve a bit more effort but are equally effective.
- Check Referral Traffic: Analyze your site’s referral traffic in Google Analytics. Look for unusual spikes or unfamiliar domains.
- Review Backlink Quality: Manually review the quality of backlinks. Check for domains with poor content or excessive ads.
- Inspect Domain Reputation: Use tools like Spamhaus to check the reputation of suspicious domains.
Manually identifying spam domains can be time-consuming. But it gives you a deeper understanding of your site’s backlink profile.
Basics Of Robots.txt Syntax
The Robots.txt file is a powerful tool for controlling web crawlers. It’s crucial for managing which parts of your site are accessible to search engines. Understanding the basics of Robots.txt syntax is essential for effectively blocking spam domains.
Key Directives
The Robots.txt file uses specific directives to control web crawlers. Below are the key directives:
- User-agent: Specifies the web crawler the rule applies to.
- Disallow: Prevents crawlers from accessing certain parts of your site.
- Allow: Grants access to specific parts of your site.
- Sitemap: Points to the location of your XML sitemap.
Here’s an example syntax:
User-agent:
Disallow: /private/
Allow: /public/
Sitemap: http://example.com/sitemap.xml
Common Mistakes
Many people make mistakes in their Robots.txt files. These errors can lead to unwanted indexing:
| Common Mistake | Issue |
|---|---|
| Incorrect Syntax | Leads to misinterpretation by crawlers. |
| Using Wildcards Incorrectly | Can block unintended content. |
| Not Specifying User-agent | Rules may not apply as intended. |
Always double-check your Robots.txt file for syntax errors. Use tools to validate it.
Creating A Robots.txt File
Creating a Robots.txt file is essential for managing your website’s SEO. This file guides search engine crawlers on which pages to index. It also tells them which pages to ignore. Blocking a spam domain is one of its key uses.
File Location
Your Robots.txt file must be in your website’s root directory. This is the main folder that holds all your website files. For example, if your domain is www.example.com, the file should be at www.example.com/robots.txt.
Use an FTP client or your hosting service’s file manager to access this directory. Ensure the file is named exactly as robots.txt—all lowercase, with no extra characters.
Basic Structure
A Robots.txt file follows a simple structure. It consists of user-agent and disallow directives. The user-agent specifies which crawlers the rules apply to. The disallow directive tells crawlers which URLs to avoid.
| Directive | Description |
|---|---|
User-agent |
Specifies the crawler. |
Disallow |
Specifies the URL to block. |
Here is a basic structure for blocking a spam domain:
User-agent:
Disallow: /spam-domain/
This code tells all crawlers (User-agent: ) to avoid the /spam-domain/ path.
To block multiple paths, add more Disallow directives. Each one should be on a new line.
Disallow: /spam-domain1/Disallow: /spam-domain2/
Credit: www.semrush.com
Blocking Spam Domains
Spam domains can harm your website’s performance. They can slow down your site and affect your rankings. To tackle this, you can use the robots.txt file. This guide will show you how to block spam domains effectively.
Syntax For Blocking
The robots.txt file uses simple commands. These commands tell web crawlers what to do. To block a spam domain, you need to use the Disallow directive. The basic syntax looks like this:
User-agent:
Disallow: /spam-directory/In this example, we block all user agents from accessing the /spam-directory/ path. You can modify the path to suit your needs.
Examples And Scenarios
Let’s look at some real-world examples of blocking spam domains:
- Blocking a specific directory:
User-agent:
Disallow: /spam-directory/User-agent:
Disallow: /spam-directory/
Disallow: /another-spam-directory/User-agent:
Disallow: /spam-directory/spam-file.htmlThese examples show different ways to block spam domains. You can use these techniques to protect your site.
| Scenario | Directive |
|---|---|
| Block a directory | Disallow: /spam-directory/ |
| Block multiple directories | Disallow: /spam-directory/ |
| Block a file | Disallow: /spam-directory/spam-file.html |
Use these directives in your robots.txt file. This will help you keep spam domains at bay.
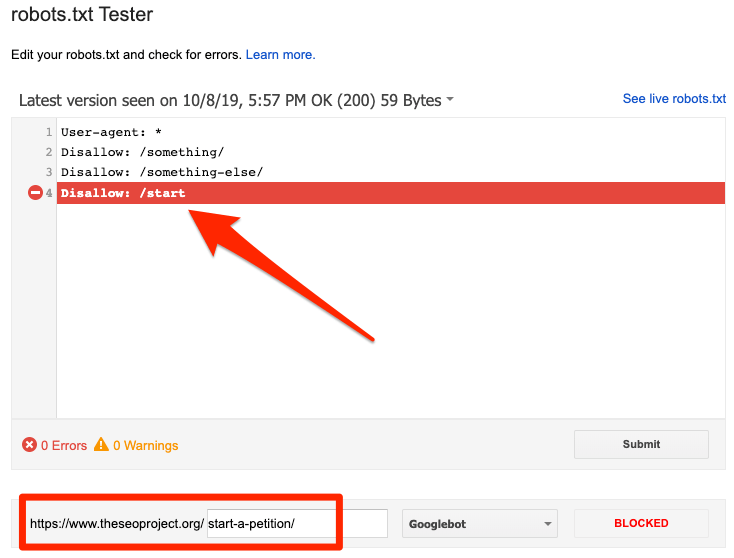
Testing Your Robots.txt
Testing your robots.txt file is crucial to ensure it’s working properly. This file tells search engines which pages to crawl or not. Blocking a spam domain through this file can enhance your website’s security and SEO. Let’s explore how to test your robots.txt file effectively.
Using Google Search Console
Google Search Console offers a Robots.txt Tester tool. This tool helps validate your file’s syntax. Follow these steps to use it:
- Sign in to Google Search Console.
- Select your property from the dashboard.
- Navigate to the “Robots.txt Tester” under Crawl.
- Paste your robots.txt content into the tester.
- Click “Test” to see if any errors appear.
If errors exist, correct them in your robots.txt file. Then, test again. This ensures your spam domain block functions correctly.
Other Testing Tools
Several other tools can help test your robots.txt file. Here are a few options:
- SEOBook Robots.txt Tester: Simple and easy to use.
- SEMrush Robots.txt Checker: Detailed analysis and recommendations.
- Yoast SEO Plugin: Ideal for WordPress users.
These tools provide insights and help you fix errors. Using multiple tools ensures thorough testing and better results.
Below is an example of a basic robots.txt file blocking a spam domain:
User-agent:
Disallow: /bad-directory/
Disallow: /spam-domain/
Remember, testing your robots.txt file is vital. It protects your site and improves your SEO.
Credit: ahrefs.com
Maintaining Your Robots.txt
Maintaining your robots.txt file is crucial for website health. This file tells search engines which parts of your website to crawl. Keeping it updated ensures that unwanted domains are blocked. This helps in managing spam and improving site performance.
Regular Updates
Regular updates to your robots.txt file are necessary. Over time, new spam domains may appear. Adding these to your file keeps your site safe. Use the following code to block a spam domain:
User-agent:
Disallow: /spam-domain/
Be sure to review your file monthly. This helps catch new spam domains quickly. Always backup your robots.txt file before making changes.
Monitoring Effectiveness
Monitoring the effectiveness of your robots.txt file is key. Check your site’s analytics regularly. Look for reduced spam activity. If spam persists, consider additional measures.
Use tools like Google Search Console for monitoring. These tools help identify any issues. They also provide insights into search engine behavior.
Here is a simple checklist for monitoring:
- Review site analytics weekly
- Check Google Search Console
- Update robots.txt as needed
Follow this checklist to ensure your site stays spam-free.
Best Practices
Blocking a spam domain in your robots.txt file can protect your site. Follow these best practices to ensure effectiveness and compliance. This will also help avoid common pitfalls.
Ensuring Compliance
Ensure your robots.txt file complies with search engine guidelines. This avoids unintentional blocking of useful crawlers. Here’s how:
- Use the correct syntax.
- Keep the file in your site’s root directory.
- Test the file using Google Search Console.
Here is an example of a correctly formatted entry:
User-agent:
Disallow: /spam-domain/
Always double-check for errors in your robots.txt file. This ensures that legitimate bots are not blocked.
Avoiding Common Pitfalls
Common mistakes can render your robots.txt file ineffective. Here are some tips to avoid these pitfalls:
- Do not use wildcards incorrectly.
- Avoid blocking essential directories.
- Regularly update your robots.txt file.
Incorrect wildcard usage can block unintended pages. For example:
User-agent:
Disallow: /spam-This might block pages with “spam” in their URL, which may be legitimate.
Blocking essential directories can harm your site’s SEO. Always review changes before implementation.
Credit: kinsta.com
Frequently Asked Questions
What Robots.txt Block Crawlers?
Robots.txt block crawlers by specifying rules for search engine bots. It restricts or allows access to website pages.
How do I disallow an URL?
To disallow a URL, add a “Disallow” directive to your robots. txt file. Specify the path you want to block. For example: “` User-agent: * Disallow: /example-page/ “`
How To Block Crawlers From Accessing The Entire Website?
To block crawlers, create a “robots. txt” file. Place it in your website’s root directory. Add “User-agent: *” and “Disallow: /”. This stops all crawlers.
Is Ignoring Robots.txt Legal?
Ignoring robots. txt is not illegal, but it is considered unethical. Respect website owners’ preferences.
What Is A Robots.txt File?
A robots. txt file instructs search engine bots on which pages to crawl or avoid.
Why Block Spam Domains In Robots.txt?
Blocking spam domains prevents them from crawling and indexing your site, improving security and SEO.
Conclusion
Blocking spam domains in your robots. txt file is crucial for website health. It helps protect your site from unwanted traffic. Follow the steps outlined to ensure your site remains efficient and secure. Regularly update your robots. txt to keep up with new spam domains.
This simple action can greatly enhance your site’s performance.







